“How’s your disaster recovery plan?”
That’s not the sort of question you’d hear at a typical Sunday afternoon barbeque, but it’s an important question, nonetheless. Of course, the person asking the question could be asking the barbeque host if they have a backup gas bottle in case this one runs out, or if there is some other plan in place. All of which is perfectly valid, even if it is a little confronting.
The host may have a range of potential solutions should the gas bottle run out. They may indeed have a full, spare bottle so that everything can keep flowing after a short interruption. Maybe their neighbour could fire up their barbeque, and everything could be passed over the fence. But the neighbour’s barbeque is smaller, so it is going to take longer to cook everything. This means that some food won’t even make it onto the plate to be cooked. Typically, it’s the vegetables that will miss out, which will annoy quite a few people (and rightly so). It also means that Cousin Jeff’s lamb, apricot, orange rind and parmesan sausages won’t touch the flame, although that'll only annoy Jeff and everyone else is perfectly fine with that.
Now, what if the host had two barbeques? Twin altars of charred perfection running side by side, each delivering different mouth-watering, flame-grilled feasts fit for barbeque royalty. Chicken, kebabs and veggies on one side, steak, sausages and lamb on the other, and both barbequing onions to perfection because, onions.
And when it’s all done, the chefs meet in the middle, aprons billowing in the fragrant, charring smoke of delicious victory, and smacking their tongs together in the most suburban of high-fives.
But, I digress. Or do I?
High Availability (HA) is the equivalent of the spare gas bottle. You may have a spare (insert a critical piece of equipment here), or some form of clustering/HA pair that can tolerate a single hardware failure. Whilst this does perform the invaluable role of catering for a failed device, it is not a proper DR solution. It does not cater for the loss of an entire site due to power, air conditioning, or other environmental failures.
To ensure continued running against a total site failure, many companies have a DR site. Much like the neighbour’s barbeque, these can be brought online in the event of a disaster. Also, like the neighbour’s barbeque, such sites cannot often run all services. This means that some functions, often related to development and testing, won't be available for the duration of the disaster.
In addition to this, maintaining a DR site, be it hot or cold, is expensive in terms of setup and maintenance. So, why not do something a little different, and run two (or more) active barbeques… er… sorry, datacentres?
It makes sense to think along those lines. Instead of having a datacentre and equipment sitting there doing nothing, put it to work. Make one datacentre the main site for one group of services, and the other the main site for the remaining services. Each can then act as the backup site for the other and, just like that, you have reduced your dormant footprint and still have redundant datacentres.
When you throw public cloud into the mix, it makes even more sense. When you are only charged for what you consume (plus storage, plus IP reservations, plus other hidden charges), you can dramatically reduce the cost of one or both of your datacentres.
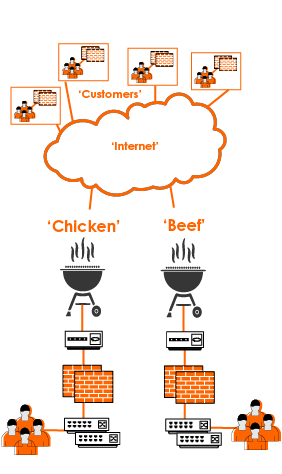
Of course, it isn’t quite that simple. How do you decide what services to run where? How do you switch between sites? How do you ensure that your users can access services once they have switched over? What do you call these datacentres now that the terms “Prod” and “DR” don’t really fit anymore, and most importantly, where do the onions fit into all of this?
Thinking about what services to place where is an interesting task and should be the subject of a comprehensive workshop, preferably held in conjunction with a company-sponsored barbeque. How you switch between sites, and how you make sure the users follow can be done in multiple ways. A robust automation and orchestration regime could manage this process for you, even down to making firewall and DNS changes, assuming you manage your DNS.
So, what about those onions? Well, stretching load balancing or clusters between both sites is one way of ensuring that data and users are served from, and have access to, both locations. A solid data replication scheme ensures that both sides are in step, with tongs in hand and ready to serve.
What about the data centre names? It's a more interesting question than you might think. DC1 and DC2, whilst close to my heart, are not entirely appropriate as they tend to designate one site as more important than the other. Some companies call them “blue” and “green”, others label them by their geographic location, such as “Sydney” and “Not Sydney” er… sorry, “Melbourne”.
Or, you could call them “chicken” and “beef”.
If you liked this blog, you may also like:
The success behind our project delivery